Letter Playground
Link straight from the Liste Typo: http://www.letterplayground.com/
15.05.10
— Sébastien Le CallonnecHere are the characters on the revised Wikipedia globe after several errors were corrected. These characters represent the first letter of “Wikipedia” in different languages.
It is also interesting to note that the “W” in the favicon is actually not a “W”, but two overlapping “V”s.
11.05.10
— Sébastien Le Callonnecsebastien@greystones:/tmp$ dos2unix mystuff.txt dos2unix: command not found
Huh?
$ sudo apt-get install tofrodos $ sudo ln -sf /usr/bin/fromdos /usr/bin/dos2unix $ sudo ln -sf /usr/bin/todos /usr/bin/unix2dos $ dos2unix mystuff.txt
Ah!
7.05.10
— Sébastien Le CallonnecNow, let’s have a look at a classic “problematic” situation illustrating this problem. This example will use PHP/MySQL, as this is quite simple to set up.
First, let’s create a database, with a table storing in latin-1:
sebastien@greystones:~$ mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 91 Server version: 5.1.41-3ubuntu12 (Ubuntu) Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> CREATE DATABASE sandbox; Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE sandbox.a (val VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_general_ci NOT NULL); Query OK, 0 rows affected (0.08 sec)
CHARACTER SET defines the encoding used, whereas COLLATE indicates which set of rules are to be used for character comparison (for sorting). For more details, see the MySQL documentation. When creating a new database, the default character set is latin1, and the default collation is latin1_swedish_ci, unless you have specified otherwise when starting mysqld or changed these values wen creating or altering the db. So, so far, we have a database that only deals with latin-1.
Let’s now have a look at the PHP page:
<?php
print '<?xml version="1.0" encoding="utf-8" ?>';
$con = mysql_connect("localhost","root","toto");
if (!$con) {
die('Could not connect: ' . mysql_error());
}
mysql_select_db("sandbox", $con);
// Insert values
if (isset($_POST["val"])) {
$val = $_POST["val"];
mysql_query("INSERT INTO a (val) VALUES ('$val')") or die(mysql_error());
}
// Retrieve values
$values = array();
$result = mysql_query("SELECT val FROM a");
while ($row = mysql_fetch_array($result)) {
$values[] = $row["val"];
}
mysql_close($con);
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Test Form</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<form action="index.php" method="post">
<fieldset>
<legend>Stuff</legend>
<input type="text" name="val" maxlength="255" />
<input type="submit" name="Submut" value="Go" />
</fieldset>
</form>
<?php if (count($values) > 0): ?>
<ul>
<?php foreach ($values as $v): ?>
<li><?= $v ?></li>
<?php endforeach; ?>
</ul>
<?php endif; ?>
</body>
</html>
(Note: this PHP file is rather simplistic, there is no validation, or anything, and everything is stuffed in the same file; not to be used in real life!) As you can see from the XML directive, as well as the Content-Type meta, we are working with the UTF-8 character set. If we use this form to enter the word “écho” in the database, we get the following:
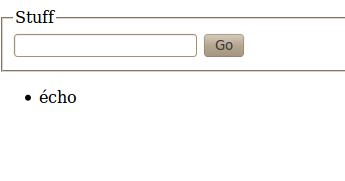
Everything looks fine. However, in phpMyAdmin:
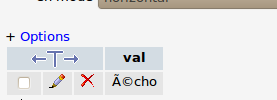
Looks familiar? Here, the web page assumes UTF-8, but stores the data in latin-1. If you go from UTF-8 to latin-1, and then back to UTF-8, you’ll obviously get the same thing:
sebastien@greystones:~$ iconv -f iso-8859-1 -t utf-8 é é sebastien@greystones:~$ iconv -f utf-8 -t iso-8859-1 é é
However, if the page had displayed the result in latin-1 (like phpMyAdmin does, presumably based on the encoding of the database), we would have had the same funky result.
What about the opposite then? Now we assume the data is stored in UTF-8, and the page is iso-8859-1.
mysql> DROP DATABASE sandbox; Query OK, 1 row affected (0.00 sec) mysql> CREATE DATABASE sandbox CHARACTER SET utf8 COLLATE utf8_unicode_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE sandbox.a (val VARCHAR(255) NOT NULL); Query OK, 0 rows affected (0.09 sec)
The page is “made” latin-1 by removing the xml directive, and charset is changed to iso-8859-1. And here is the result:
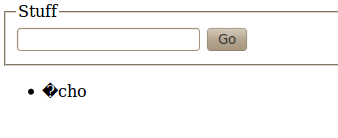
Also:
mysql> SELECT val from sandbox.a; +------+ | val | +------+ | �cho | +------+ 1 row in set (0.00 sec)
The replacement character (�) appears. Why? “é” is 0xE9 in latin-1, that is 11101001, which is not a possible value for UTF-8 (as we have seen, 1-byte long characters start with a 0. 3-byte characters do start with the 1110 sequence, but the following octet should start with 10 – it’s not the case as the following character is c, (0x63 in latin-1, i.e. 01100011), so as something is obviously wrong, the replacement character is displayed.
Also, in the news, First IDN ccTLDs now available (IDN stands for Internationalized Domain Name).
Comment [1]
30.04.10
— Sébastien Le CallonnecAs I said before, encoding issues are quite common, and yet, they can be very tricky to debug: the reason is that any link in the long chain between the data storage (sql or not) and the client can be the culprit and has to be investigated. I have recently experienced this first hand, and it was tricky enough to be the object of a future post.
In short, the problem was that a PDF document produced by PDFLaTeX in iso-8859-1 was incorrectly forced into UTF-8, therefore corrupting the binary file as a result. The sure sign of this was that single characters were “converted” into 2 or more characters, for example: “é” was displayed as “é”. Anybody who’s worked on non-ASCII projects (probably 98% of the non English-speaking world) has had a similar problem, I’m sure.
But why does “é” become “é”, why that particular sequence:
sebastien@greystones:~$ iconv -f latin1 -t utf8 é é?
The reason lies in the UTF-8 representation. Characters below or equal to 127 (0x7F) are represented with 1 byte only, and this is equivalent to the ASCII value. Characters below or equal to 2047 are written on two bytes of the form 110yyyyy 10xxxxxx where the scalar representation of the character is: 0000000000yyyyyxxxxxx
(see here for more details).
“é” is U+00E9 (LATIN SMALLER LETTER E WITH ACUTE), which in binary representation is: 00000000 11101001. “é” is therefore between 127 and 2027 (233), so it will be coded on 2 bytes. Therefore its UTF-8 representation is 11000011 10101001.
Now let’s imagine that this “é” sits in a document that’s believed to be latin-1, and we want to convert it to UTF-8. iso-8859-1 characters are coded on 8 bits, so the 2-byte character “é” will become 2 1-byte-long latin-1 characters. The first character is 11000011, i.e. C3, which, when checking the table corresponds to “Ô (U+00C3); the second one is 10101001, i.e. A9, which corresponds to “©” (U+00A9).
What happens if you convert “é” to UTF-8… again? You get something like “Ã?©” (the second character can vary). Why? Exactly the same reason: “Ô (U+00C3) is represented on 2 bytes, so it becomes 11000011 10000010 (C3 82), and “©” (U+00A9) becomes 11000010 10101001 (C2 A9). U+00C3 is, as we saw Ã, U+0082 is BPH (“Break Permitted Here”, which does not represent a graphic character), U+00C2 is Â, and U+00A9 is, as we saw, ©.
Update:
Just a few points to clarify the above, as the use of iconv above may be slightly confusing.
11000011 10101001 is read as the two 1-byte latin-1 characters é, rather than the 2-byte UTF-8 character éiconv converts from one character code to another. This means that an UTF-8 “é” becomes an iso-8859-1 “é” when converting from UTF-8 to another. The sequence is therefore converted from 0xC3 0xA9 to 0xE9. Let’s see this:sebastien@greystones:~$ echo é > /tmp/test.txt sebastien@greystones:~$ xxd /tmp/test.txt 0000000: c3a9 0a ... sebastien@greystones:~$ iconv -f utf8 -t iso-8859-1 /tmp/test.txt --output=/tmp/test_1.txt sebastien@greystones:~$ xxd /tmp/test_1.txt 0000000: e90a .. sebastien@greystones:~$
In the example in the post:
sebastien@greystones:~$ iconv -f latin1 -t utf8 é é
I know that the character entered on the console is UTF-8, but I ask iconv to consider it as latin-1, and then to convert it to UTF-8 to illustrate the problem.
I hope this clarifies things a bit.
Update: second part of the article here.
Comment [9]
1.04.10
— Sébastien Le CallonnecTo install the mysql gem for Ruby 1.9.1 on Ubuntu Lucid, you need the headers so that it gets compiled properly. What I did to install it was:
sudo apt-get install libmysqlclient15-dev sudo gem install mysql
27.03.10
— Sébastien Le CallonnecAs you probably know, when shooting landscape, there are two “magic” times: dawn, about 30 min before sunrise, till 30 min after, and dusk. According to Scott Kelby, some magazines do not even consider looking at pictures if they are not taken at either of these 2 times. So this morning I got up at 5 am (something I don’t remember doing willingly in yonks), and headed to Greystones beach. Not that I intend to publish pictures or anything, but I do want nice pictures.
I. Loved. it. Every second of it. The sunrise was amazing, the birds flying around was a real pleasure, the village looked peaceful in the distance, the sea was quite soothing (had I needed soothing at 6 in the morning…), and no one about. Cleared my head, put a big smile on my face, and at first glance, there are one or two focusandshootable pictures in the lot…
The new tripod is awesome. It is very light and though it can sometimes be a bit of a problem, it wasn’t this morning: no wind at all, and I certainly enjoyed its lightness (and its bag) whilst walking around. I used bracketing a bit, but having looked at the result, it appears the correctly exposed picture is the keeper.
Now in the future, I’ll probably have to be a bit more organized: I was lucky enough to wear a coat with large pockets, handy enough to put stuff like lens caps, but dropping a lens in the sand because I forgot to close my camera bag was rather high on the scale of idiocy… Also, I didn’t realise the camera was set to ISO 400, which I’m a bit annoyed about: a bit of a bummer if you use a tripod.
26.03.10
— Sébastien Le CallonnecComme c’est un mot à la mode, je ne résiste pas au plaisir de partager avec vous sa définition :
Une palinodie (du grec πάλιν (palin), de nouveau, et ὠδή (ôdê), chant) est un texte dans lequel on contredit ce que l’on avait affirmé auparavant.
18.03.10
— Sébastien Le CallonnecPHP recently stopped interpreting PHP scripts in public_html after a (Lucid) Ubuntu update: instead of displaying the generated HTML, it was just offering to download the script — the kind of “new” behaviour that leaves you baffled for a few minutes…
After reinstalling apache and PHP without any luck, I looked into Apache configuration, and in the PHP5 mod, here is what I found:
<IfModule mod_userdir.c>
<Directory /home/*/public_html>
php_admin_value engine Off
</Directory>
</IfModule>
The PHP engine is explicitly disabled in public_html, yes sir. Comment out the bit above using hashes, restart your Apache server (sudo service apache2 force-reload), and you’re sorted.
Not sure why this change has been made, though.
Comment [5]
16.03.10
— Sébastien Le CallonnecIf you were walking your dog, or running on Dun Laoghaire pier last night, you may have seen a group of weirdos walking around with their tripod and camera, and waiting for a long time to get the right shot. Well, that was us.
It has been really fun, I must admit, and I’ve learnt quite a fair bit. I’m still really frustrated with my camera and my own skills; but I feel I’m getting somewhere. Now it is time to practice even more, and I guess I’ll keep an eye out for a photography club or something in Wickla!
If you’re interested in the results of the shoot, I have posted a few pictures on focusandshoot.net, so they’ll be appearing in the next couple of weeks: stay tuned!
11.03.10
— Sébastien Le CallonnecAfter long hours of hair pulling, I gave my little Spring MVC app a go in a different app server (namely, GlassFish), and realised that my Expression Language expressions were working just fine there, whereas they were not getting evaluated at all in Google apps.
Well, turns out, that’s known issue. Just add:
<%@page isELIgnored="false"%>
at the top of your JSP, and it works.
8.03.10
— Sébastien Le CallonnecJe dois dire que j’avais un tantinet tiqué1 à la lecture des nouvelles règles Fiba il y a quelques temps : repousser la ligne des 3 points à 6,75 m et faire de la raquette un rectangle me paraissait être un formidable baissage de culotte des Européens face à un NBA omniprésent sur la scène basketballistique. Même si je persiste à croire que l’initiative de ces changements a pour honteuse raison de vouloir-faire-comme-en-NBA-et-de-rendre-tout-le-monde-content-aux-JO-et-aux-championnats-du-monde-surtout-la-dream-team, Jean-Luc Thomas offre un début de justification acceptable dans sa dernière chronique : favoriser l‘écartement du jeu avec la possibilité de créer plus d’espace pour les intérieurs (même si agrandir la zone restrictive ne colle pas avec cette logique) qui, du fait de la chute du nombre de paniers primés, seront plus sollicités.
Mouais. Admettons.
1 Euphémisme, cough, cough.
12.02.10
— Sébastien Le CallonnecRock, Paper, Scissors 12/2/2010
Another Java forum classic: rock, paper, scissors. Or chifoumi, as it is called in France.
An interesting solution involves an enum (which I called Choice below). The only “fancy” thing in the code is checkWinner which checks if the first value is equal to the second value + 1, modulo 3 (as paper is stronger than rock, scissors stronger than paper, and rock stronger than scissors, so there’s a circular thing going on there). I haven’t bothered checking the user’s input, but that should really be done.
import java.util.Random; import java.util.Scanner;public class RockPaperScissors { public enum Choice { ROCK(0), PAPER(1), SCISSORS(2);private final int value;Choice(int value) { this.value = value; }public int value() { return value; } }private int checkWinner(Choice choice1, Choice choice2) { if (choice2 == choice1) { return 0; } else if (choice1.value() == ((choice2.value() + 1) %3)) { return 1; } else return 2; }private Choice getChoiceAtRandom() { return Choice.values()[new Random().nextInt(3)]; }private Choice readChoice() { System.out.println("Rock, paper or scissors?"); Scanner scanner = new Scanner(System.in); String choice = scanner.next(); return Choice.valueOf(choice.toUpperCase()); }public void doGameLoop() { int counter = 0; while (counter < 3) { Choice userChoice = readChoice(); Choice computerChoice = getChoiceAtRandom();int winner = checkWinner(userChoice, computerChoice); if (winner == 0) { System.out.println("Both " + userChoice + ". It's a tie"); } else if (winner == 1) { System.out.println("You win! You played " + userChoice + " and computer played " + computerChoice) ; } else { System.out.println("You lose. You played " + userChoice + " and computer played " + computerChoice) ; }counter++; } }public static void main(String[] args) { new RockPaperScissors().doGameLoop(); } }
And that’s pretty much it — connoisseurs will appreciate the use of Scanner which I usually spit upon!
I highly recommend reading the Wikipedia entry for Rock, paper, scissors, it’s quite entertaining… Did you know it’s been used in a (US) federal court?!
8.02.10
— Sébastien Le CallonnecFinally, an interesting question! Where does System.out come from? In the aforementioned thread, I have posted an explanation that simplified what was happening behind the scene; but very much in line with Don Knuth spirit, I gave you a white lie: this is not entirely the whole truth. Though the general idea is still the same. I’ll shamelessly copy-paste some of my own response, because yes, I’m that lazy.
(All the explanation below is based on the OpenJDK 6 sources, so it might be slightly different in other VMs)
When you first look at the code in the System class, you get quite confused:
// ... public final static InputStream in = nullInputStream(); // ... public final static PrintStream out = nullPrintStream(); // ... public final static PrintStream err = nullPrintStream();// ... private static PrintStream nullPrintStream() throws NullPointerException { if (currentTimeMillis() > 0) { return null; } throw new NullPointerException(); }
So it either returns null, or a NullPointerException?? First, let’s have at currentTimeMillis(), which is part of the condition:
public static native long currentTimeMillis();
currentTimeMillis is a native method. Native methods are methods implemented in another language (usually C or C++). This method is mapped to its C counterpart thanks to the following JNI mechanism:
public final class System { private static native void registerNatives(); static { registerNatives(); }// ...
registerNatives is defined in what we call a static block, which is a block of code called only once, at classloading time. Static blocks are used for example in JDBC when you do Class.forName("my.nice.Driver"): the driver class has a static block with which it registers itself with the DriverManager, and allows you to then use the DriverManager for, say, giving you a connection. So here, the static block calls a native method, and this native method executes the C code below (Open JDK) in System.c:
static JNINativeMethod methods[] = { {"currentTimeMillis", "()J", (void *)&JVM_CurrentTimeMillis}, {"nanoTime", "()J", (void *)&JVM_NanoTime}, {"arraycopy", "(" OBJ "I" OBJ "II)V", (void *)&JVM_ArrayCopy}, };#undef OBJJNIEXPORT void JNICALL Java_java_lang_System_registerNatives(JNIEnv *env, jclass cls) { (*env)->RegisterNatives(env, cls, methods, sizeof(methods)/sizeof(methods[0])); }
So I kind of lied when I said in my post that the streams were initialized by registerNatives. Well, not entirely, you’ll see why.
So when initializing the class variables out, in and err, currentTimeMillis should be defined, and these final variables are then set to null. If you get a NullPointerException, something utterly wrong has happened, and the JVM will probably shut down.
System gets initialized at a very specific point in the whole vm startup: it is loaded when the main thread is being kickstarted. In a file called thread.cpp, the following piece of code is executed:
// Initialize java_lang.System (needed before creating the thread) if (InitializeJavaLangSystem) { initialize_class(vmSymbolHandles::java_lang_System(), CHECK_0);// ...call_initializeSystemClass(CHECK_0);
And there you go: the System class gets loaded, and the static block is executed. We now have access to currentTimeMillis, and streams out, err and in will be null. Further down, the call_initializeSystemClass(CHECK_0) function is called, and that’s the function that actually calls the private method initializeSystemClass that calls the native methods setIn0, setOut0 and setErr0 which do initialize the streams properly.
Why are these setters (setIn0, setErr0 and setOut0) native? It’s because they are initializing final variables a second time, since they had already been set to null. Making them native allows the VM to bypass the language restriction to completely initialize the streams.
Once the VM is loaded, and again if nothing dramatic has happened, then System is available for business, along with its streams! This concludes this post, but hopefully this should the first post of new series I’m thinking of writing, called “The JVM in depth”.