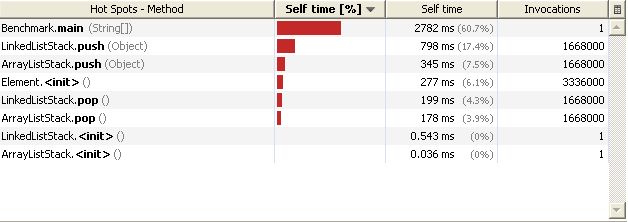
JTrees on their own are pretty dumb: they can’t do much. One thing they are good at though, is to get others to do their job. For example, to display the nodes, it asks the TreeModel what these nodes are.
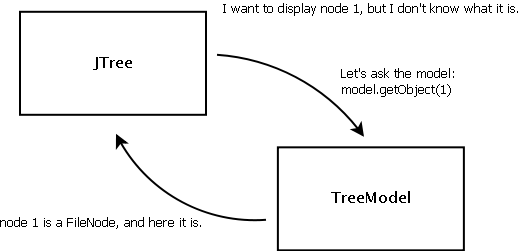
They don’t know how to display either: they need to use other types of objects, called renderers.
In the previous episode of the JTree saga, we were displaying folders and files, but one problem that we didn’t mention was that empty folders, or folders that are not accessible, were displayed with a “file” icon. The reason for this is that getChildrenCount(Object node) in our model returns 0 for these folders, so JTree treat them as leaves.
We are going to fix this by using a TreeCellRenderer. In FilePreviewer, we now add the following:
tree.setCellRenderer(new DefaultTreeCellRenderer() {
@Override
public Component getTreeCellRendererComponent(
JTree tree,
Object value,
boolean sel,
boolean expanded,
boolean leaf,
int row,
boolean hasFocus) {
// Call parent rendering to keep the default behaviour
super.getTreeCellRendererComponent(
tree, value, sel,
expanded, leaf, row,
hasFocus);
// And now specific stuff
File currentFile = (File) value;
// If the current node is a directory, and if it has no child,
// or if they are not accessible, change the icon.
if (currentFile.isDirectory() && (currentFile.list() == null || currentFile.list().length == 0)) {
if (expanded) {
setIcon(openIcon);
} else {
setIcon(closedIcon);
}
}
return this;
}
});
Our renderer calls the default rendering, and for folders whose children either don’t exist or are not accessible, we change the icon: if the node is expanded, we use openIcon, other we use closedIcon.
Adding a bit of sorting, we start to get a nice file previewer:
import java.io.File;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import javax.swing.event.TreeModelListener;
import javax.swing.tree.TreeModel;
import javax.swing.tree.TreePath;
public class FileSelectorModel implements TreeModel {
private FileNode root;
/**
* the constructor defines the root.
*/
public FileSelectorModel(String directory) {
root = new FileNode(directory);
}
public Object getRoot() {
return root;
}
/**
* returns the <code>parent</code>'s child located at index <code>index</code>.
*/
public Object getChild(Object parent, int index) {
FileNode parentNode = (FileNode) parent;
List<File> children = getSortedChildren(parentNode);
return new FileNode(parentNode,
children.get(index).getName());
}
/**
* returns the number of child. If the node is not a directory, or its list of children
* is null, returns 0. Otherwise, just return the number of files under the current file.
*/
public int getChildCount(Object parent) {
FileNode parentNode = (FileNode) parent;
if (parent == null
|| !parentNode.isDirectory()
|| parentNode.listFiles() == null) {
return 0;
}
return parentNode.listFiles().length;
}
/**
* returns true if {{@link #getChildCount(Object)} is 0.
*/
public boolean isLeaf(Object node) {
return (getChildCount(node) == 0);
}
/**
* return the index of the child in the list of files under <code>parent</code>.
*/
public int getIndexOfChild(Object parent, Object child) {
FileNode parentNode = (FileNode) parent;
FileNode childNode = (FileNode) child;
List<File> children = getSortedChildren(parentNode);
return children.indexOf(childNode);
}
private List<File> getSortedChildren(File node) {
List<File> children = Arrays.asList(node.listFiles());
Collections.sort(children, new Comparator<File>() {
public int compare(File o1, File o2) {
if (o1.isDirectory() == o2.isDirectory()) {
return o1.getName().compareTo(o2.getName());
}
if (o1.isDirectory()) {
return -1;
}
return 1;
}
});
return children;
}
// The following methods are not implemented, as we won't need them for this example.
public void valueForPathChanged(TreePath path, Object newValue) {
}
public void addTreeModelListener(TreeModelListener l) {
}
public void removeTreeModelListener(TreeModelListener l) {
}
}
And in the FilePreviewer class, I’ve added a split pane:
import java.awt.*;
import java.io.*;
import javax.swing.*;
import javax.swing.event.*;
import javax.swing.tree.DefaultTreeCellRenderer;
public class FilePreviewer extends JFrame {
private JTree tree;
private JTextArea preview;
private JLabel status;
public FilePreviewer(String directory) {
tree = new JTree(new FileSelectorModel(directory));
preview = new JTextArea();
preview.setWrapStyleWord(true);
preview.setLineWrap(true);
preview.setEditable(false);
status = new JLabel(directory);
tree.addTreeSelectionListener(new TreeSelectionListener() {
public void valueChanged(TreeSelectionEvent e) {
FileNode selectedNode = (FileNode) tree.getLastSelectedPathComponent();
status.setText(selectedNode.getAbsolutePath());
if (selectedNode.isFile()) {
preview.setText(null);
try {
BufferedReader br = new BufferedReader(new FileReader(selectedNode.getAbsolutePath()));
String line = "";
while ((line = br.readLine()) != null) {
preview.append(line);
preview.append(System.getProperty("line.separator"));
}
} catch (Exception exc) {
exc.printStackTrace();
}
}
}
});
tree.setCellRenderer(new DefaultTreeCellRenderer() {
@Override
public Component getTreeCellRendererComponent(
JTree tree,
Object value,
boolean sel,
boolean expanded,
boolean leaf,
int row,
boolean hasFocus) {
// Call parent rendering to keep the default behaviour
super.getTreeCellRendererComponent(
tree, value, sel,
expanded, leaf, row,
hasFocus);
// And now specific stuff
File currentFile = (File) value;
// If the current node is a directory, and if it has no child,
// or if they are not accessible, change the icon.
if (currentFile.isDirectory() && (currentFile.list() == null || currentFile.list().length == 0)) {
if (expanded) {
setIcon(openIcon);
} else {
setIcon(closedIcon);
}
}
return this;
}
});
JSplitPane split = new JSplitPane(JSplitPane.HORIZONTAL_SPLIT,
new JScrollPane(tree),
new JScrollPane(preview));
split.setContinuousLayout(true);
getContentPane().add(BorderLayout.SOUTH, status);
getContentPane().add(split);
setSize(800, 600);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setTitle("Quick'n'Dirty File Preview");
setVisible(true);
}
public static void main(String[] args) {
new FilePreviewer(File.listRoots()[1].getAbsolutePath());
}
}
The final small change is in FileNode: we display the path is the name is empty, so that the root appears correctly:
public class FileNode extends java.io.File {
public FileNode(String directory) {
super(directory);
}
public FileNode(FileNode parent, String child) {
super(parent, child);
}
@Override
public String toString() {
return (getName().length() == 0 ? getPath() : getName() );
}
}