Now, let’s have a look at a classic “problematic” situation illustrating this problem. This example will use PHP/MySQL, as this is quite simple to set up.
First, let’s create a database, with a table storing in latin-1:
sebastien@greystones:~$ mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \\g. Your MySQL connection id is 91 Server version: 5.1.41-3ubuntu12 (Ubuntu) Type ’help;’ or ’\\h’ for help. Type ’\\c’ to clear the current input statement. mysql> CREATE DATABASE sandbox; Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE sandbox.a (val VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_general_ci NOT NULL); Query OK, 0 rows affected (0.08 sec)
CHARACTER SET defines the encoding used, whereas COLLATE indicates which set of rules are to be used for character comparison (for sorting). For more details, see the MySQL documentation. When creating a new database, the default character set is latin1, and the default collation is latin1_swedish_ci, unless you have specified otherwise when starting mysqld or changed these values wen creating or altering the db. So, so far, we have a database that only deals with latin-1.
Let’s now have a look at the PHP page:
<?php
print ’<?xml version="1.0" encoding="utf-8" ?>’;
$con = mysql_connect("localhost","root","toto");
if (!$con) {
die(’Could not connect: ’ . mysql_error());
}
mysql_select_db("sandbox", $con);
// Insert values
if (isset($_POST["val"])) {
$val = $_POST["val"];
mysql_query("INSERT INTO a (val) VALUES (’$val’)") or die(mysql_error());
}
// Retrieve values
$values = array();
$result = mysql_query("SELECT val FROM a");
while ($row = mysql_fetch_array($result)) {
$values[] = $row["val"];
}
mysql_close($con);
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Test Form</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<form action="index.php" method="post">
<fieldset>
<legend>Stuff</legend>
<input type="text" name="val" maxlength="255" />
<input type="submit" name="Submut" value="Go" />
</fieldset>
</form>
<?php if (count($values) > 0): ?>
<ul>
<?php foreach ($values as $v): ?>
<li><?= $v ?></li>
<?php endforeach; ?>
</ul>
<?php endif; ?>
</body>
</html>
(Note: this PHP file is rather simplistic, there is no validation, or anything, and everything is stuffed in the same file; not to be used in real life!) As you can see from the XML directive, as well as the Content-Type meta, we are working with the UTF-8 character set. If we use this form to enter the word “écho” in the database, we get the following:
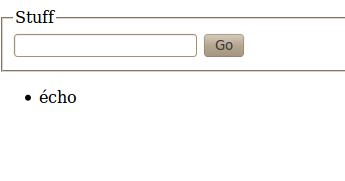
Everything looks fine. However, in phpMyAdmin:
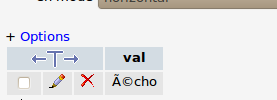
Looks familiar? Here, the web page assumes UTF-8, but stores the data in latin-1. If you go from UTF-8 to latin-1, and then back to UTF-8, you’ll obviously get the same thing:
sebastien@greystones:~$ iconv -f iso-8859-1 -t utf-8 é é sebastien@greystones:~$ iconv -f utf-8 -t iso-8859-1 é é
However, if the page had displayed the result in latin-1 (like phpMyAdmin does, presumably based on the encoding of the database), we would have had the same funky result.
What about the opposite then? Now we assume the data is stored in UTF-8, and the page is iso-8859-1.
mysql> DROP DATABASE sandbox; Query OK, 1 row affected (0.00 sec) mysql> CREATE DATABASE sandbox CHARACTER SET utf8 COLLATE utf8_unicode_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE sandbox.a (val VARCHAR(255) NOT NULL); Query OK, 0 rows affected (0.09 sec)
The page is “made” latin-1 by removing the xml directive, and charset is changed to iso-8859-1. And here is the result:
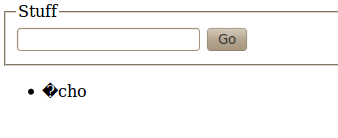
Also:
mysql> SELECT val from sandbox.a; +------+ | val | +------+ | �cho | +------+ 1 row in set (0.00 sec)
The replacement character (�) appears. Why? “é” is 0xE9 in latin-1, that is 11101001, which is not a possible value for UTF-8 (as we have seen, 1-byte long characters start with a 0. 3-byte characters do start with the 1110 sequence, but the following octet should start with 10 – it’s not the case as the following character is c, (0x63 in latin-1, i.e. 01100011), so as something is obviously wrong, the replacement character is displayed.
Also, in the news, First IDN ccTLDs now available (IDN stands for Internationalized Domain Name).