PHP and UTF-8
PHP characters (5 and prior) are one-byte long. When working with UTF-81, this becomes an incredible royal PITA and an endless source of frustration, even for people used to work with characters present in latin-1. Even more annoying, some functions such as htmlentities, htmlspecialchars, etc. just assume latin-1 by default, and you have to remember to explicitly set the encoding, e.g.:
htmlentities($string, ENT_COMPAT, 'UTF-8');
But it also has some extremely annoying consequences for simple string functions such as substr or strlen. Typically:
$ echo '<?php echo strlen("é"); ?>' | php
2
Let’s look at an example seen this morning on a popular literary French blog running on the also popular platform Wordpress:
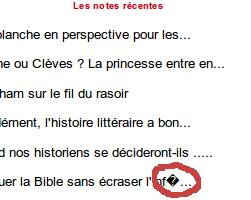
And here is more than likely what happened here: characters in PHP are one-byte long, but as we have seen in the past, characters in UTF-8 strings may be longer than one-byte (up to 4). â belongs to the Latin-1 supplement group, and is encoded on 2 bytes: C3 A2. As substr only deals with 1-byte characters, it simply cut “â” in the middle, leaving C3 in, and getting rid A2. C3 on its own is obviously invalid UTF-8, so it is replaced by the replacement character. Here is a file simulating this:
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> </head> <body> <p> <?php $text = "Critiquer la Bible sans écraser l’infâme"; echo substr($text, 0, 41); ?> </p> </body> </html>
The solution is to use the multi-byte strings functions—but they have to be included in the PHP installation explicitly, as mbstring is a non-default extension. Here is an example with mb_substr:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<p>
<?php
mb_internal_encoding("UTF-8");
$text = "Critiquer la Bible sans écraser l’infâme";
echo mb_substr($text, 0, 37);
echo "<br />";
echo mb_substr($text, 0, 38);
?>
</p>
</body>
</html>
(You will probably notice that I changed the index after which the string is truncated. That’s because strlen is also based on 1-byte character, so when it counts the characters in a string that contains UTF-8 characters encoded with more than 1 byte, it “sees” more characters… So as mbstring functions now can deal with multi-byte characters, we have to cut the string earlier to see whether “â” avoids the chop.)
AFAIK, PHP 6 will have Unicode support, so it will be the end of all this craze, but it’s something to take into account when dealing with PHP 5 apps…
1 UTF-8 is a popular encoding on the Web mainly because it is a variable width encoding where ASCII characters are encoded on one byte, most of European, Cyrillic, Arabic, Hebrew ones on 2 bytes, and the rest of the world use 2, 3 or 4 byte-long characters (so it made the English-speaking users happy as (1) writing text in ASCII is “automatically” in UTF-8, as the two match, and (2) it doesn’t increase the size of their file).
Hi,
I’m having this exact problem, but I’m not using any string functions except for echo. The strings I am echoing come from an exec($cmd, $out, $return) command, and I echo them like this:
for ($i = 0; $i < sizeof($out); $i++) { echo $out[$i]; echo “\n”;
}
I know the characters are coming correctly from the exec’d program because when I do this:
for ($i = 0; $i < sizeof($out); $i++) fwrite($errFile, $out[$i].”\n”);
… the files get the correct characters. But when they make it back to the client from the echo, I get the diamond question mark for the latin-1 characters.
Any suggestions would be appreciated!
Thanks,
Sam.
— Sam Scott · 2012-08-01 20:24 · #